Successful automation projects
From bank statement analysis to complex invoice recognition: discover how EasyData transforms organizations with proven AI solutions. 25+ years of Dutch expertise in document processing for more efficient processes and improved compliance.

Why do organizations choose EasyData?
For an IT manager at a municipality it seemed impossible: automatically processing thousands of bank statements from different banks without storing any privacy-sensitive information. That changed when he discovered the Financial Search solution from EasyData.
This introduction perfectly illustrates what this article is about: how EasyData helps organizations automate complex document processing using European technology and its own data centers. In this article, you will discover concrete examples of successful projects, from invoice recognition to handwriting recognition, and why these solutions are more relevant than ever.
With increasing digitalization and stricter privacy requirements, organizations are looking for reliable partners that can guarantee both innovation and compliance. EasyData combines more than 25 years of experience with cutting-edge cloud solutions, offering a unique proposition in the market.
Bank statement analysis for Dutch municipality

Dutch municipalities face the challenge of processing bank statements from various banks (ABN Amro, ING, Rabobank and SNS) quickly and securely. We solved the core of this problem with our Financial Search technology, which automatically recognizes documents, extracts relevant data and categorizes transactions according to a dynamic system.
The unique aspect of this approach is that categories do not contain personal data and can, if desired, be shared with other connected municipalities. This creates a network of best practices that can be widely reused.
Key benefits for the client:
- Full privacy: No storage of personal data. Processing takes place in a strictly secured environment
- Flexibility: Category structures can easily be adapted to changing regulations
- Security: Files are delivered via secure channels and deleted immediately after processing
- Scalability: Suitable for high document volumes with transparent tiered pricing
- Extensibility: Other document types can be added in addition to bank statements
The implementation also included a service desk portal, user logging and extensive support. Thanks to this integrated approach, the connected municipalities can organize their financial processes more efficiently and securely while fully preserving privacy and compliance.
Automatic invoice processing for mid-sized company

A successful project involved automating the invoice processing workflow for a mid-sized Dutch company. The goal was to minimize manual processing of incoming PDF invoices and significantly increase administrative efficiency.
Incoming PDF invoices are automatically recognized at line level. Invoices that already contain an XML file are forwarded directly to the desired server location. Recognized invoices are placed via a secure connection into a folder that is directly accessible to the customer’s ERP system.
Special functionalities:
Online verification: Invoices that cannot be fully recognized automatically are routed to an online verification module. If manual correction is required, the responsible employee automatically receives an email notification.
Continuous improvement: Customers can easily submit poorly recognized invoices for process optimization, allowing the system to become smarter over time.
Concrete results:
- Time savings: Processing is largely automatic, allowing staff to focus on higher-value tasks
- Reliability: Fewer errors due to automatic recognition and controls
- Cost reduction: Competitive per-invoice pricing and fewer manual activities
- Customization possible: Processing of summary or atypical invoices according to specific requirements
OCR enhancement for healthcare sector
For a leading organization in the healthcare sector, we carried out an innovative project focused on improving the recognition of hard-to-read documents. A significant portion of the submitted documents could not be recognized automatically by existing OCR systems.
We developed an advanced image enhancement module based on machine learning and OpenCV. This module corrects perspective, fixes distortions and increases resolution so documents are optimally prepared for automatic recognition.
Technical innovations:
Hybrid OCR workflow: After image enhancement, only the relevant document parts are recognized via a secure workflow using Azure Advanced OCR. This safeguards privacy and speeds up processing.
Document splitting and merging: Our technology splits documents into logical, recognizable segments, then combines the results into a single, clear text file with PDF references.
Results for the client:
- Higher recognition rate: Significantly more documents are recognized automatically
- More efficient workflow: Document processing lead times have been reduced substantially
- Scalability: Suitable for large document volumes and extendable with new technologies
- Cost savings: Direct savings in time and operational costs due to less manual work
Complex invoice recognition for international organization
For an internationally operating organization we carried out a project that focused on automating complex invoice processing. The client was struggling with high dependence on manual processing, error sensitivity and limited flexibility.

We implemented an advanced solution that automatically recognizes invoices and extracts key data such as suppliers, amounts, VAT rates and currencies directly from documents. This was achieved by combining template recognition with machine learning.
Special characteristics:
Scalable integration: Fully integrated with the existing ERP system for a seamless workflow and prevention of duplicate entries.
Flexible adjustments: Specific requirements around VAT handling and multi-currency support were realized using custom rules. Organizations can easily respond to changing laws and regulations.
Concrete improvements:
- Shorter lead times for invoice processing*
- Drastic error reduction compared to manual data entry
- Fast onboarding of new suppliers and invoice formats
- International scalability: Supports multiple currencies and VAT regimes
Automated mailroom processing for government organization

For a government organization, we executed a project fully focused on modernizing the processing of incoming mail and documents. The challenge was to efficiently process both paper and digital mail flows, guarantee privacy and establish integrations with existing case management systems.
We implemented a solution where both physical and digital documents are centrally scanned, recognized and automatically enriched with relevant metadata. A distinction is made between technical and content-related metadata, tailored to the organization’s requirements.
Innovative functionalities:
Integration with case systems: Scanned documents are offered via secure integration to the case system after recognition and classification. This makes it possible to use documents directly as the starting point for new cases.
AI and OCR technology: By using advanced OCR and AI models, documents are accurately recognized and classified. Handwriting recognition (ICR) and QR code recognition are also integrated.
Results for the organization:
- Efficient mail processing: Lead times are greatly reduced and errors minimized
- Flexibility: Modular architecture that is easy to extend with new document types
- Cost savings: Reduced manual work and optimal use of existing infrastructure
- Privacy and control: Full control over data and processes with maximum privacy protection
Identity document recognition for telecom sector
For a major player in the telecom and technology sector, we carried out a project focused on optimizing the scanning and recognition of various documents, such as identity documents, bank cards, receipts and Chamber of Commerce extracts.
Using our EasyData OCR Technology, documents such as passports, ID cards, driver’s licenses and bank cards are automatically recognized and relevant data is extracted. For European identity documents, the MRZ (Machine Readable Zone) is used as the basis for fast and reliable data extraction.
Privacy by design:
To comply with GDPR requirements, anonymized training data is used wherever possible. If fully anonymized processing is not feasible, datasets are constructed where one of the main fields is anonymized at all times so the privacy of end users remains safeguarded.
Concrete benefits:
- Higher reliability: Fewer errors when adding and processing documents
- Efficiency and time savings: Manual checks are largely unnecessary
- Privacy and compliance: Full adherence to privacy legislation through anonymized data
- Smooth implementation: Modular setup and central control for fast rollout
Automatic drawing recognition for manufacturing industry
For a leading company in the manufacturing industry, we delivered an advanced project focused on automating technical document processing and performing complex calculations based on drawings. The challenge was to automatically extract data from welding drawings, validate it and immediately translate it into accurate calculations for production and quality control.
Hot folder automation:
Automatic document processing: Digital drawings are automatically imported via a hot folder as soon as they are placed in the correct directory. The system directly processes PDF files with vector images and text layers, making manual uploads or sorting unnecessary.
Using machine learning, specific welding symbols and relevant parameters, such as material type, plate thickness, weld length and angle, are automatically recognized and extracted from the drawings. Missing or unclear fields are flagged so users can easily supplement or correct them via a user-friendly web portal.
Results for the client:
- Efficiency: Processing time for technical documents is drastically reduced
- Accuracy: Automatic recognition and validation minimize human errors
- Ease of use: Simple review and data completion via web portal
- Full privacy: Local processing without an internet connection for optimal security
Identity document recognition for telecom sector
For a major player in the telecom and technology sector, we carried out a project focused on optimizing the scanning and recognition of various documents, such as identity documents, bank cards, receipts and Chamber of Commerce extracts.
Using our EasyData OCR Technology, documents such as passports, ID cards, driver’s licenses and bank cards are automatically recognized and relevant data is extracted. For European identity documents, the MRZ (Machine Readable Zone) is used as the basis for fast and reliable data extraction.
Privacy by design:
To comply with GDPR requirements, anonymized training data is used wherever possible. If fully anonymized processing is not feasible, datasets are constructed where one of the main fields is anonymized at all times so the privacy of end users remains safeguarded.
Concrete benefits:
- Higher reliability: Fewer errors when adding and processing documents
- Efficiency and time savings: Manual checks are largely unnecessary
- Privacy and compliance: Full adherence to privacy legislation through anonymized data
- Smooth implementation: Modular setup and central control for fast rollout
Automatic drawing recognition for manufacturing industry
For a leading company in the manufacturing industry, we delivered an advanced project focused on automating technical document processing and performing complex calculations based on drawings. The challenge was to automatically extract data from welding drawings, validate it and immediately translate it into accurate calculations for production and quality control.
Hot folder automation:
Automatic document processing: Digital drawings are automatically imported via a hot folder as soon as they are placed in the correct directory. The system directly processes PDF files with vector images and text layers, making manual uploads or sorting unnecessary.
Using machine learning, specific welding symbols and relevant parameters, such as material type, plate thickness, weld length and angle, are automatically recognized and extracted from the drawings. Missing or unclear fields are flagged so users can easily supplement or correct them via a user-friendly web portal.
Results for the client:
- Efficiency: Processing time for technical documents is drastically reduced
- Accuracy: Automatic recognition and validation minimize human errors
- Ease of use: Simple review and data completion via web portal
- Full privacy: Local processing without an internet connection for optimal security
Material certificates in international industry
For an international industrial organization, we carried out a project focused on automatically reading and structuring complex certificate documents, such as material certificates for steel and other metals. The challenge was that these documents were semi-structured: tables and data appeared in many different forms and layouts.

Layout-specific extraction:
Tailored per document type: Based on the documents received, six unique layouts were identified. For each layout, a dedicated extraction module was developed, aligned with the specific structure and presentation of the data. This guarantees high accuracy even for atypical or less structured tables.
To further improve extraction quality, reference lists were used for material types, “Heat No.” formats and diameter ranges. This minimizes errors when reading and validating values and ensures deviations are flagged immediately.
Concrete results:
- Efficiency: Manual entry and checking largely replaced by automatic extraction
- Reliability: Validation against reference lists improves data quality
- Ease of use: Upload and processing via a secure NextCloud environment
- Future-proof: New document types can easily be added
Historical archive digitization

For an archive institution dealing with large volumes of historical documents, including maps with handwritten notes, dossiers and inventory lists, we carried out a project focused on automating recognition and digitization of both handwritten and typed text. The challenge was the wide variety of handwriting styles, pencil notes and varying scan and paper quality.
Multi-engine approach:
Combined technologies: We used different OCR and HTR systems, including EasyData OCR, Yandex Vision and Transcribus, to automatically recognize handwritten and mixed texts. By combining these systems intelligently, the chance of successful extraction increased significantly.
For documents with faint pencil notes or low scan resolution, image enhancement modules were applied. The recognized text was used directly to index documents and enrich them with metadata, making them searchable in the archive system.
Impactful results:
- Drastic time savings: Processing time per document reduced by a factor of 3 to 5
- Better accessibility: Archive items become fully searchable for researchers
- Higher data quality: Validation with word lists improves accuracy
- Privacy and compliance: Processing in a secure environment according to archive standards
End-to-end automation in financial services
For an international service provider in the financial sector, we executed a project aimed at fully automating the processing of various documents, such as contracts, invoices and customer forms. The organization was dealing with large volumes of documents entering daily via multiple channels (email, uploads, cloud folders).
No-code flexibility:
User-friendly configuration: Automation was configured for different document types, including invoices, contracts, shipping labels and customer forms. Thanks to a no-code interface, staff can easily create and adjust templates without programming knowledge.
We set up a workflow in which documents are automatically collected from different sources, recognized, categorized and enriched with relevant data using AI-driven OCR and machine learning technology. The extracted data is automatically validated and passed directly to back-end systems.
Measurable improvements:
- Time savings: Processing time reduced from hours to seconds
- Fewer errors: Error rates in data entry reduced drastically
- Scalability: Easily processes large volumes, even during peak periods
- Cost savings: Lower operational costs due to less manual work
Fraud detection for government organization
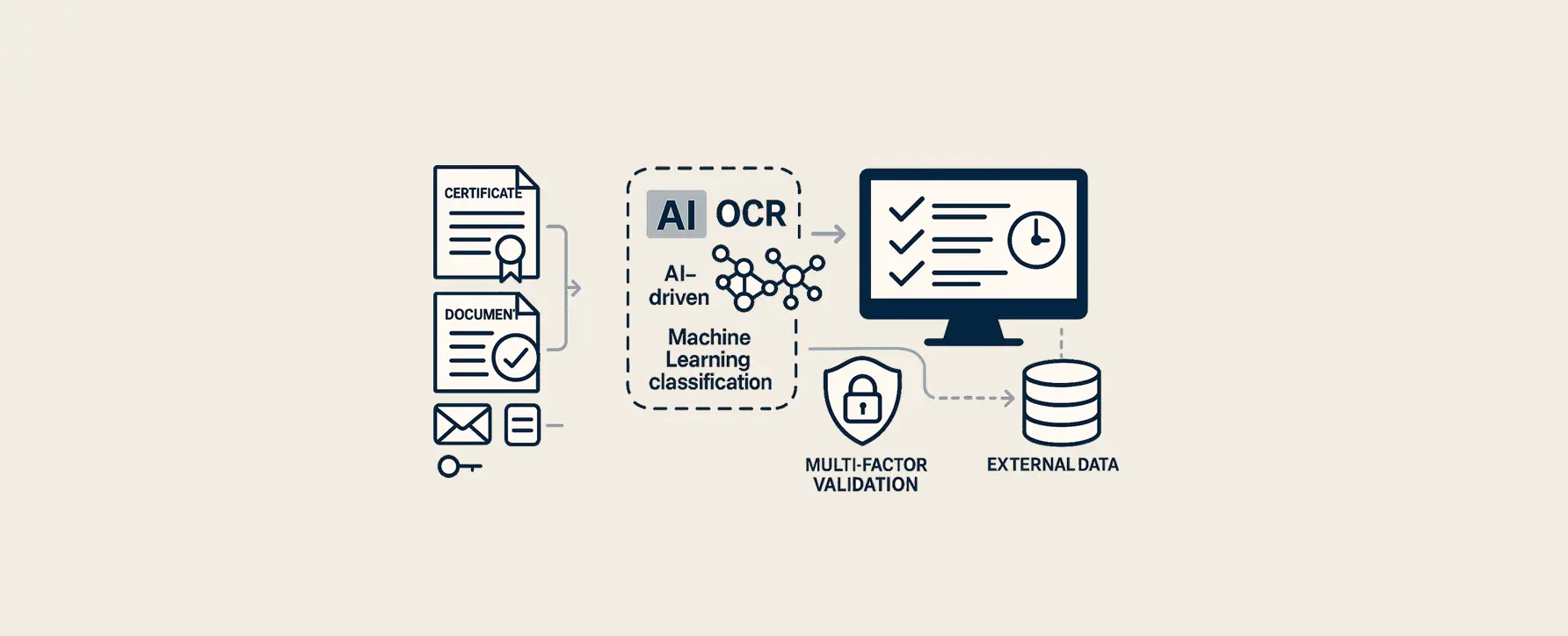
For a government organization, we developed an innovative project focused on automating the processing and validation of certificates and trade documents. The challenge was to quickly and reliably distinguish between legitimate and fraudulent documents, recognizing and analyzing both handwritten and machine-printed text.
External data integration:
Multi-source validation: Where necessary, additional information is automatically retrieved from trusted online sources to strengthen validation and guarantee completeness. This significantly increases the reliability of fraud detection.
Using our own OCR technology and handwriting recognition modules, documents are read with high precision and missing or unclear data is automatically flagged. Documents are classified and validated using reference lists and metadata.
Security and efficiency benefits:
- Fast and reliable recognition: Inspection lead times are shortened considerably
- Improved fraud detection: Deviations and potential fraud are detected more quickly
- Ease of use: Clear interface with options for manual intervention
- Privacy and compliance: Full compliance with privacy laws with minimal data storage
Automated order processing for trade and distribution company

For a trade and distribution company with a high volume of order processing, we delivered a project focused on automating and optimizing the order process. The existing solution no longer met requirements: key order details were being lost and extensive manual checking caused delays and errors.
Machine learning optimization:
Self-learning system: Orders that meet the validation threshold are directly exported as PDFs with accompanying XML data. Orders where there is uncertainty are routed to an online validation portal (EasyVerify) for manual review and model training. As a result, the system becomes smarter and the number of manual corrections decreases over time.
The system is trained to recognize essential data such as delivery address, customer number, email, IBAN, phone numbers, order numbers (from both dealer and end customer) and tables with quantities and item numbers. Unknown or incomplete data is automatically enriched via database lookup.
Business benefits:
- Efficiency: Order processing is largely automated with significantly reduced lead times
- Cost savings: Fewer manual actions and competitive pricing per processed order
- Ease of use: Simple review, training and reporting for staff
- Future-proof: Flexible, scalable and extendable with new features
Document anonymization for technology company
For a technology company specialized in data protection, we executed a project around developing and implementing an advanced solution for document anonymization. The client wanted to respond to the growing demand for privacy protection when processing large volumes of sensitive documents.

Named Entity Recognition:
Intelligent detection: By applying advanced machine learning technologies and NER models, personal data, signatures and sensitive entities are automatically recognized and anonymized. The system continuously improves based on feedback and new datasets.
We fully integrated the existing anonymization platform into a scalable cloud environment. This allows large volumes of documents to be processed quickly and securely, with page-level parallel processing for maximum speed and capacity.
Strategic results:
- Fast processing: Large volumes of documents anonymized securely in a short time
- High accuracy: Reliable detection and redaction of sensitive data
- Flexibility: Evolves with changing requirements and is easy to extend
- Market position: Solid foundation for further growth and innovation through collaboration
Financial reporting conversion for national organization

For a national organization responsible for gaining insight into large numbers of annual reports and financial statements, we carried out a project centered on converting and structuring unstructured financial documents. The challenge was to quickly and accurately extract relevant financial data from thousands of annual reports.
Automatic web crawling:
Intelligent collection: With our Financial Search solution, annual reports are automatically collected, recognized and converted into structured data. The system can search the internet for annual reports, download them and classify them based on relevant characteristics such as company name, reporting year and stock exchange listing.
By applying smart algorithms, consolidated balance sheets and other key figures were automatically recognized, checked for completeness and combined into a clear Excel file or database. The export can be fully tailored to the customer’s needs and is suitable for further analysis or monitoring.
Analytical benefits:
- Efficiency: Processing time for annual reports drastically reduced
- Reliability: Data accuracy significantly improved through automatic validation
- Insight and control: In-depth analyses possible for better decision-making
- Future-proof: Evolves with new requirements and developments
Technical drawing archive optimization for theme park
For a large Dutch theme park, we carried out a project focused on optimizing the findability and accessibility of a large technical archive. The challenge was to make thousands of technical drawings, maintenance documents and inventory lists easier to search for technical staff.
Smart metadata enrichment:
Automatic structuring: By applying smart algorithms, we were able to extract relevant data from scanned documents and enrich it with metadata. This made it possible to classify documents, for example by attraction name, document type, year or supplier.
We started with a thorough inventory of archive material for several attractions. We examined the structure of existing folders, the presence of inventory lists and the quality of technical drawings and maintenance documents. For documents with poor scan quality, image enhancement was applied.
Operational improvements:
- Fast findability: Staff can quickly search and immediately find the right documents
- Better structure: Archive
- Better structure: Archive is future-proof and flexible through metadata enrichment
- Fewer errors: Central access prevents duplicate or incomplete scans
- Extensibility: Prepared for further digitization and new document types
Transport document processing for logistics service provider

For a logistics service provider active in international trade, we delivered a project focused on automating the processing and control of transport and freight-related documents such as CMRs, loading and unloading forms and supporting certificates. The client wanted to drastically reduce manual checks and minimize compliance risks.
Compliance automation:
Automatic validation: The system automatically checks whether all required documents are present, such as tank cleaning certificates, accompanying letters and statements about previous loads. Missing or deviating documents are flagged immediately so staff can intervene quickly.
All submitted transport documents are automatically recognized and relevant data, such as PO/SO number, truck and trailer information, loading and unloading locations and product details, is extracted. The system is flexible enough to process different languages, layouts and document types, including handwritten and stamped fields.
Logistics optimizations:
- Efficiency: Processing time per transport dossier significantly reduced*
- Error reduction: Errors and compliance risks significantly decreased thanks to automatic validation
- Transparency: Documents centrally organized with full logging and audit trail
- Flexibility: Easily adaptable to new document types and compliance requirements
Claim processing for international insurer
For an international insurer, we delivered a project that transformed the entire process of handling medical claims. The challenge was to process large numbers of scanned claim forms from various insurance companies and in many formats quickly, accurately and securely.
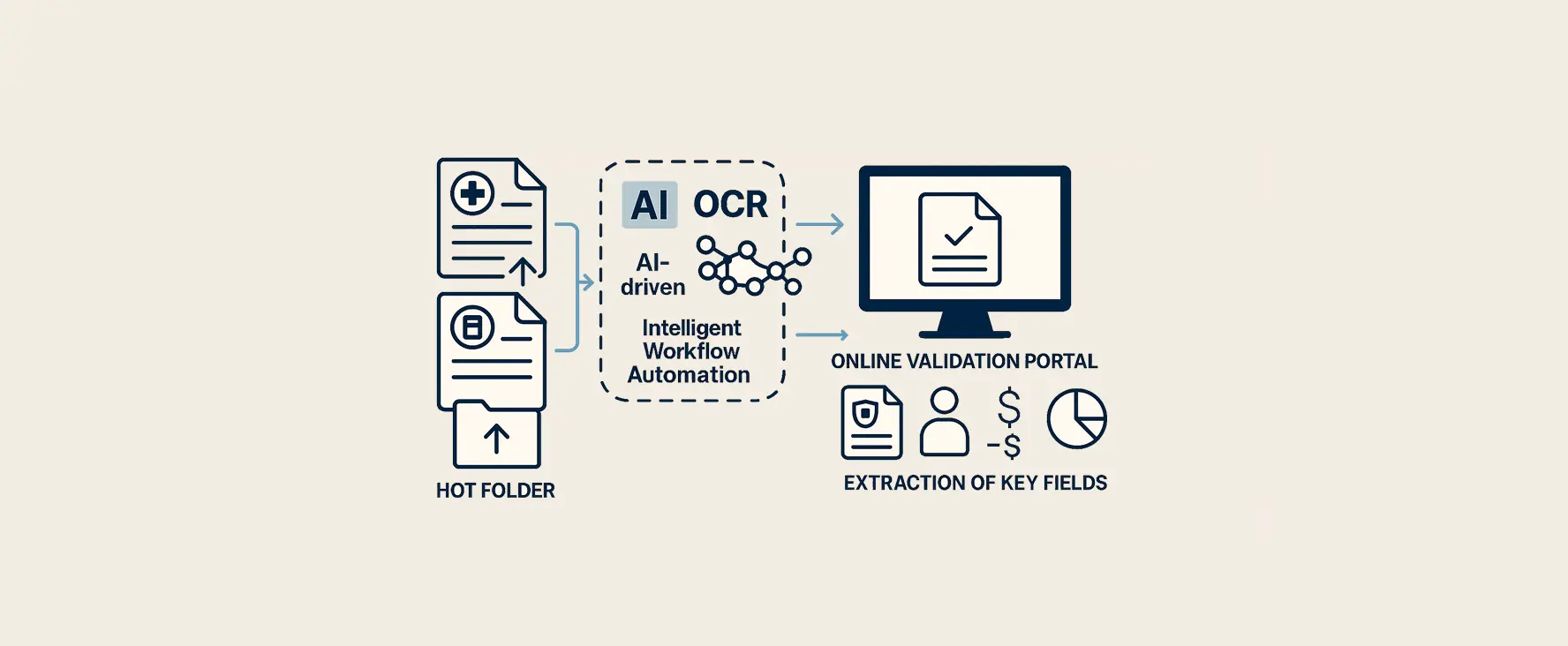
Intelligent workflow automation:
Hot folder processing: Documents are automatically picked up and processed via a hot folder. Only documents with uncertainties or missing data are sent to an online validation portal, where operators can quickly correct errors. This drastically reduces manual workload.
Using an advanced platform, scanned claim documents are automatically recognized. Important fields such as policy information, insured amounts, amounts paid and outstanding claims and breakdowns per type of care are extracted directly from the documents. The system adapts to different document structures and can quickly incorporate new templates.
Insurance-related benefits:
- Efficiency: Claim processing times significantly reduced*
- Accuracy: Number of errors and corrections greatly reduced through automatic validation
- Cost savings: Significant reduction in operational costs due to less manual work
- Future-proof: Evolves with new requirements and international expansion
WOZ objection handling for regional government
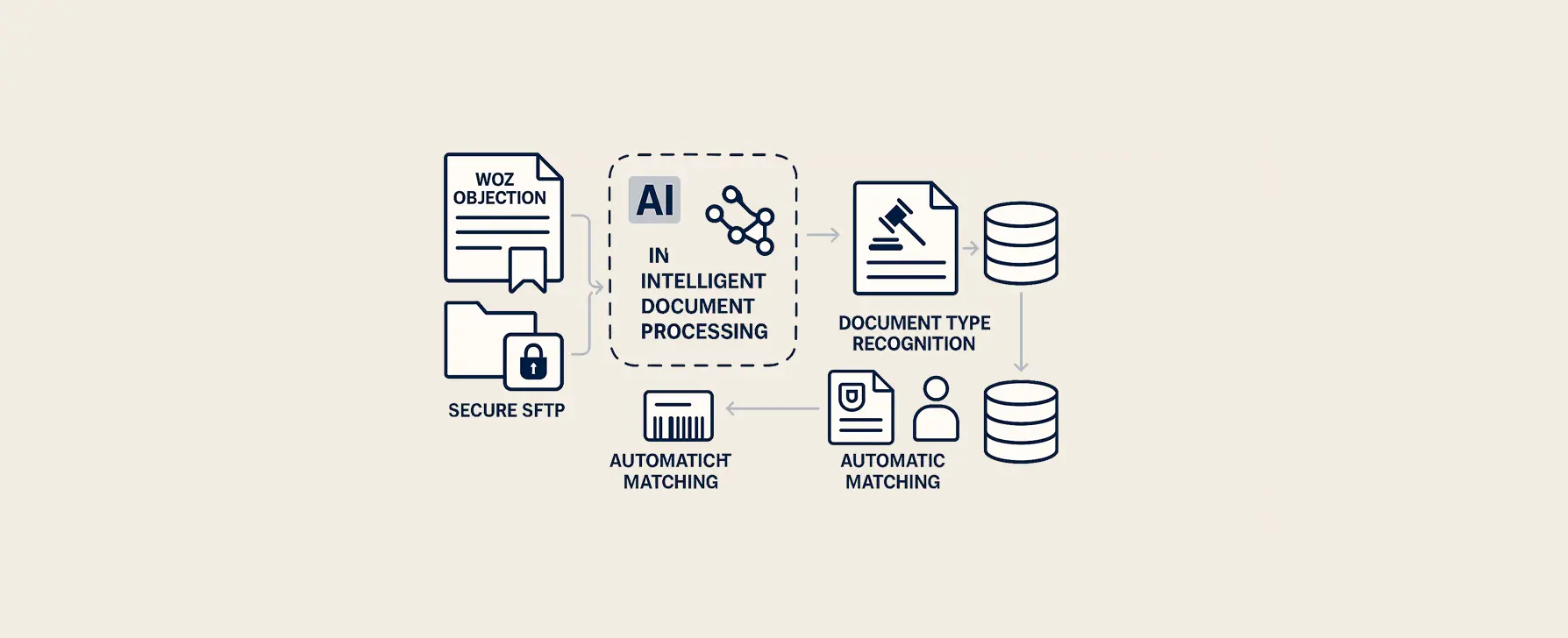
For a regional government body, we carried out a project that fully automated the processing of objection and court documents. The challenge was to efficiently and accurately link incoming WOZ objections and court documents to the correct files, integrating different document types, barcodes and databases.
Intelligent case linking:
Automatic matching: Using intelligent field recognition, relevant data such as case numbers and customer numbers is extracted. Based on the case number, additional information such as the name of the submitter is retrieved and added automatically. Barcodes are actively used to speed up recognition.
Incoming objections are automatically retrieved from a secure SFTP location. The system recognizes the document type, reads assessment and case numbers and links them directly to the correct records in the database. Court documents are recognized based on unique characteristics and matched with existing cases.
Government-specific benefits:
- Efficiency: Manual processing becomes almost unnecessary with significantly reduced lead times
- Reliability: Minimal risk of errors through automatic matching and barcode recognition
- Scalability: Easily extendable with new document types or recognition rules
- Cost control: Operational costs drop and team capacity is used optimally
Revolution in automotive document processing: from rigid templates to intelligent AI

For a leading software developer that builds and markets a powerful document management system for car dealers, we delivered a groundbreaking project. The goal was to replace their existing rigid document processing solution from a third party. That system significantly hindered customers in their daily workflows.
The challenge: 60+ document types and outdated technology
Critical limitations of the old system: The existing third-party system relied entirely on a template-based approach, where fields were tied to specific locations in documents. This made the system extremely inflexible for new document layouts. Supporting new document types took up to four days and sometimes even a week, severely limiting scalability.
Measurable results after 2 months of implementation:
- Revolutionary speed gains: Supporting new document types reduced from 4+ days to minimal configuration time
- Improved classification accuracy: AI-driven approach with confidence scoring significantly reduces manual intervention
- Higher data extraction precision: Location-independent field extraction with validation ensures consistent quality
- GDPR assurance: Automatic compliance for sensitive documents without operational impact
Enterprise ABBYY FlexiCapture Azure infrastructure

For a client whose existing ABBYY FlexiCapture implementation could not meet their requirements, we executed a large-scale infrastructure project for professional setup and support of their ABBYY FlexiCapture cloud infrastructure on Microsoft Azure. This project illustrates EasyData’s expertise in enterprise-level cloud implementations and our international service operation from our Armenian office.
Complex enterprise infrastructure: from analysis to optimization
Cost optimization with external infrastructure: To optimize costs, we implemented an external infrastructure for backup by deploying off-cloud infrastructure for savings. This included setting up data transfer channels and configuring synchronization processes, resulting in significant monthly savings on Azure storage costs.
Enterprise-level results after 4–6 weeks of implementation:
- Complete infrastructure setup: In 184 hours we established a professional configuration
- Automatic scaling: Load-responsive infrastructure that grows automatically with demand
- Robust backup strategies: Dual backup with cost-optimized external infrastructure
- Database performance: Optimized FlexiCapture database with automatic maintenance
- 6-month warranty: Quality guarantee on all work performed
Intelligent credit processing

For a bank that we cannot name, we delivered a groundbreaking project that transformed the entire credit approval process. The bank was struggling with extremely long lead times for processing mortgage, car and consumer credit applications sent via their CRM system from branches across the country. Manual verification of scanned documents formed a critical bottleneck.
Complex document challenge: no standard formats
Unique technical challenge: The main challenge was the lack of standardized formats for salary certificates and contracts. Hundreds of different layouts had to be processed reliably. EasyData developed a hybrid approach that combines algorithms with machine learning to successfully handle this extreme variation.
Measurable impact for the bank:
- Major time reduction: Approval times shortened multiple times over thanks to automated verification
- Improved customer experience: Significantly faster response times for credit applications
- Error reduction: Neural network models reduce errors in validating signatures and stamps
- Scalability: Solution grows with new product lines and branches
Why these projects were successful
These cases show that successful document automation is not only about the latest technology. It is mainly about understanding specific customer needs and delivering solutions that really work in practice.
Common success factors:
European technology and compliance: All projects were delivered with EasyData’s own technology, hosted in Dutch data centers according to European privacy standards.
Customization within standard frameworks: Each solution was tailored to specific requirements but built on proven technical foundations.
Hands-on implementation: Through intensive collaboration and knowledge transfer, customers were enabled to work independently with their systems.
From bank statement analysis to handwriting recognition, from invoice processing to fraud detection, each project shows how thoughtful automation helps organizations work more efficiently, accurately and securely. The secret lies in combining advanced AI technology with deep understanding of business processes and a pragmatic implementation approach.
Are you curious how EasyData can transform your document processes as well? These projects prove that effective automation is within reach, regardless of how complex your document flows are.
Ready to move from manual chaos to smart automation?
Join the organizations that have already automated their document processing. Experience for yourself how improved accuracy and substantial time savings can transform your organization and possibly go live within 8 weeks.*
💼 Dutch automation expertise guaranteed
25+ years of experience – Pioneers in document automation since 1999
Dutch data sovereignty – All servers in own data centers, full GDPR compliance
No vendor lock-in – Open standards and full data ownership
8-week implementation – From first contact to working solution
Transparent pricing – No hidden costs or unclear licenses
European compliance – GDPR-ready with Dutch data center location
*Implementation timeframe based on average project duration for Dutch customers. Individual projects may vary depending on organization size and complexity.
Frequently asked questions about document automation
How long does it take to implement a document automation solution?
Implementation time varies depending on complexity and scope. Simple invoice recognition can typically be operational within 2–4 weeks, while more complex solutions such as full mailroom processing can take 2–3 months.* EasyData stands out with short implementation times by using proven technical frameworks.
What privacy safeguards does EasyData offer?
All EasyData solutions are hosted in Dutch data centers according to European privacy standards. We work with privacy-by-design principles, anonymized training data where possible and offer both cloud and on-premise implementations. Customers retain full control over their data.
Can existing systems be integrated?
Yes. EasyData specializes in seamless integration with existing ERP, CRM and case management systems. By using standard APIs, XML export and custom connectors, we ensure new automation integrates with your current IT infrastructure without major disruption.
What are the typical cost savings?
Dutch customers report substantial reductions in processing time, drastic decreases in data entry errors and significantly lower operational costs.* Exact savings depend on the current process and document volumes, but ROI is typically achieved within 12–18 months.
How accurate is automatic document recognition?
Accuracy depends on document type and quality. For structured documents such as invoices, we achieve high accuracy levels.* For more complex documents such as handwritten text, results are within acceptable ranges. All systems include validation workflows for human review where needed.
Is staff training required?
EasyData provides comprehensive training and documentation with every implementation. Thanks to user-friendly interfaces and no-code configuration, staff can quickly become self-sufficient. We offer both on-site training and online workshops tailored to your organization.
*Results based on internal measurements for Dutch customers. Individual results may vary per organization and process scope.
📝 About the author
